项目地址:https://gitee.com/vnpycn/vnpy
网址:http://www.vnpy.cn
快速入门: https://q.vnpy.cn/comm/thread-13-1-1.html

在新版VNPY3.0中,已经彻底放弃对数据库的支持。
不少用户肯定会问,没有数据库支持,还是一个专业的量化软件吗?数据该如何存储?
国内证券和期货软件,比如恒生,大智慧,同花顺,文华财经,金字塔均不需要用户安装数据库
原因很简单,就是数据库太慢了。
有多慢呢?在我的单机环境下测试结果:
读取性能:csv文件比关系型数据库读取速度快2个数量.
数据占用空间: csv文件只有关系型数据库的 1/5~1/25。
NOSQL内存数据库也只是相对比关系型数据库快一点而已,并没有本质区别。
即便是时序数据库,性能也远远低于csv或hdf5文件格式。
是不是很颠覆三观呢?
不得不提到某些鼓吹使用数据库的量化平台,鼓吹使用数据库成为“割韭菜”的利器,促进了培训课程销售, 而这些培训结构讲师本身并不是依靠量化本身盈利。
用户目的是为了学习搭建自己的量化平台,而培训结构是为了推销课程,这种结果导向不一致,会让用户付出更多的学习成本,反而取得更差的效果。
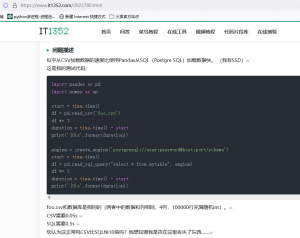
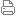
参考技术测试文章一:这是pandas读取csv和postgre,快10倍,这个测试因为是python,差距减小。 (如果要客观的测试,就应该采用C++读取csv和读数据库进行比较,而不做任何冗余的转换流程,这样既可以更精确的反映csv相对于数据库的性能,据我们的测试结果比该参考技术测试文章的15~20倍的性能差距还要显著增加) 《Pandas加载CSV的速度比SQL快 - IT屋-程序员软件开发技术分享社区 》 Pandas加载CSV的速度比SQL快 - IT屋-程序员软件开发技术分享社区
www.it1352.com/2023780.html
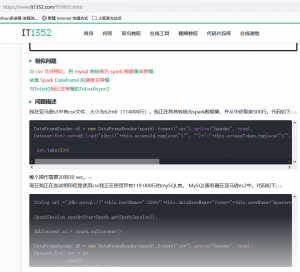
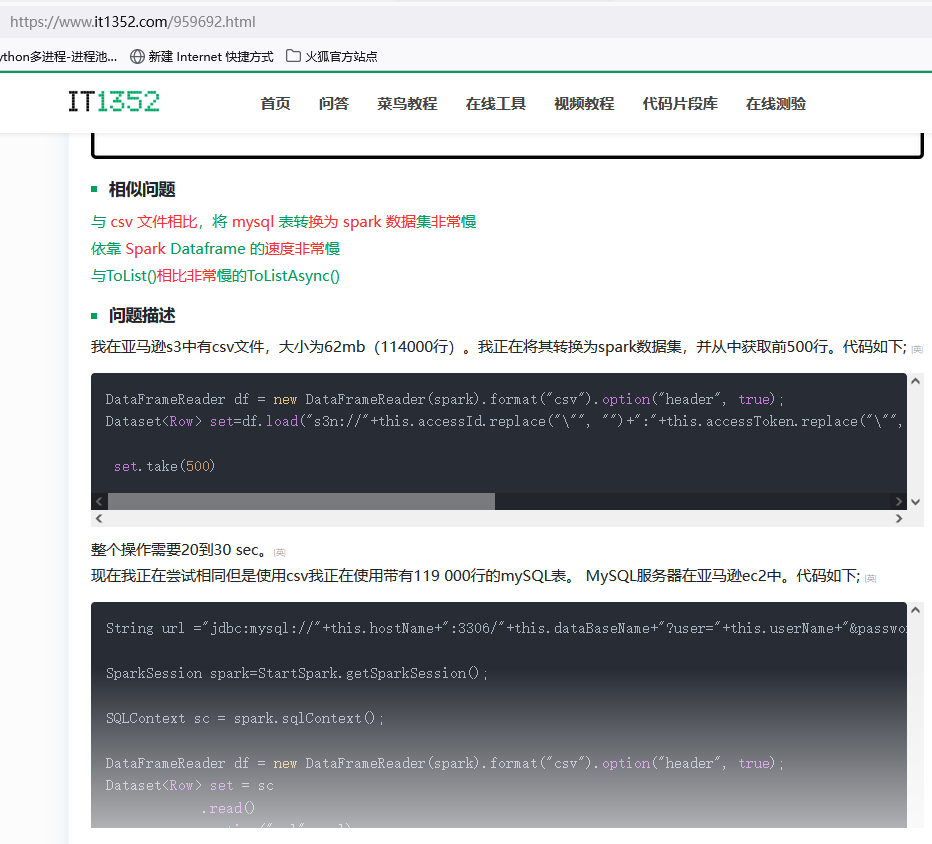
参考技术测试文章二: 结论:这个测试csv比mysql快20倍,因为涉及spark转换时间,所以只差20倍,如果忽视spanrk转换,应该接近我说的2个数量级,csv比mysql性能优势还要增加。 (如果要客观的测试,就应该采用C++读取csv和读数据库进行比较,而不做任何冗余的转换流程,这样既可以更精确的反映csv相对于数据库的性能,据我们的测试结果比该参考技术测试文章的15~20倍的性能差距还要显著增加) 与csv文件相比,将mysql表转换为spark数据集的速度非常慢 - IT屋-程序员软件开发技术分享社区
www.it1352.com/959692.html
下面就来解释一下原因。
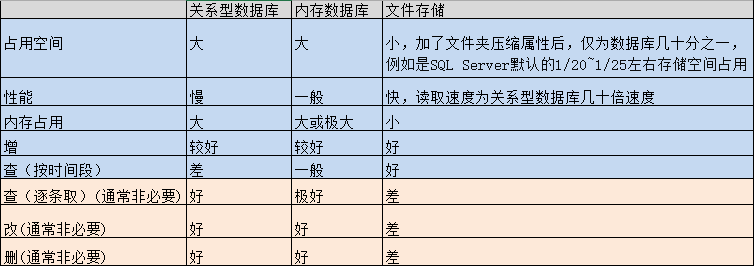
数据库需同时具备增、删、改、查 功能,而我们对量化回测数据的要求是尽可能快的读取数据
如同所示,这是csv文件格式和数据库的特点对比。
采用csv或hdf5文件格式存储,不仅更小的硬盘空间占用,还降低了读写数据IOPS的占用,
而且提高了读取性能(大约比SQL SERVER快 2个数量级,内存数据库差距会稍小,但代价是更大的内存占用),也降低了因为磁盘故障导致数据错误的可能。
量化回测时,数据是时间序列,需要连续读取行情数据。
而数据库通常属于无序的文件组织方法并不是连续存放数据的,为了便于插入数据,数据库通常中间还有无数据的填充空间。
这个性能降低在单机环境下测试比直接采用csv格式文件存储慢接近100倍。

为了方便检索数据,通常分为关系型数据库和非关系型数据库,一种是用索引的形式,一种是用HASH表的形式,这2种形式数据都不是按顺序存放的,数据和数据之间都由填充空间。
即便是时序数据库,性能也远远低于csv和hdf5文件的性能,使用也更复杂。
对量化交易回测来说,对行情数据的存储根本不需要 删、改、查功能。
拿期货行情数据为例,通常我需要将实时行情存储,如果我开启一个策略,需要计算M10 周期最近100个周期的KDJ指标,那么我只要需要最近的100X10X60X2个TICK数据即可,我只需要按时间顺序读取最近的12万个TICK。
如果是从数据库读取的话,需要通过select语句或存储过程等方式 获得记录集,并逐条取出,这个过程是非常耗时的
这个过程是非常耗时的,并且每条记录之间,按默认设置,数据库为了便于插入数据,往往在记录之间留有空白的存储空间,往往按默认设置,80%的空间是无用
的,也就是说,本来你只需要1M的空间你,实际占了5M的硬盘空间。事实上,你可能并没有插入数据的请求。因为行情数据存储都是顺序的,按时间顺序写入之
后,通常不需要再插入新的行情数据。
对“查”来说,也并不是逐条取得,通常是取一个时间段的数据,并不是数据库方式的 “查”数据的方式。
而且由于数据库的IO较慢。有人说,可以用内存数据库啊,事实上内存数据库会占用大量的内存空间,而且他的快也只是和关系型数据库比,远远慢于CSV和hdf5格式。
用文件存储是一个更好的选择,事实上很多知名的股票软件公司都采用文件存储行情数据的。
比如文件存储怎么做呢?
例如按一个规则制定:
比如rb2110的2021年6月5日的TICK行情数据,就存储在
..\data\20211005\TICK\rb2110.csv 目录的文件下
该文件将顺序存储当天的TICK数据。
当我需要读取最近3天数据的时候,就按先后分别读取
..\data\20211005\TICK\rb2110.csv
..\data\20211006\TICK\rb2110.csv
..\data\20211007\TICK\rb2110.csv
这3个文件即可, 每个文件逐行读取。
如果需要进一步节省硬盘存储空间,我可以将data文件夹设置为 压缩属性。
在没有设置压缩属性的情况下,采用文件方式存储数据大约占用硬盘空间是采用SQL Server默认设置的20%硬盘空间。
在设置了data文件夹的压缩属性的情况下,采用文件方式存储数据大约占用硬盘空间是采用SQL Server默认设置的4%硬盘空间。
VNPY官网
http://www.vnpy.cn
| 








 发表于
发表于 

 QQ好友和群
QQ好友和群 收藏
收藏